Purpose
The purpose of this post is to document the expected behaviour of the 3PAR StoreServ 7×00 and VMware Site Recovery Manager in both a ‘planned failover’ and ‘unplanned failover’.
Envrionment
The tests where performed on two different environments each containing the same infrastructure.
- vCenter 5.5 Update 2 (Build 2001466)
- Site Recovery Manager 5.8.0 (Build 2056894)
- HP 3PAR SRA 5.5.2.285
- HP 3PAR Inform OS 3.1.3 (MU1) P03, P07, P09
3PAR Details
Prominent details about the 3PAR configuration are highlighted below.
- Single common provisioning group used for virtual volumes and remote copy space
- Auto LUN ID used
- Auto Recover enabled
- A Synchronous replication using 15 minute interval schedule
- Virtual Volumes are presented to a Host Set at Source Site and are ‘Exported
- Virtual Volumes are presented to a Host Set at Target Site and are ‘Un-Exported’
During the tests, I was logged into the source and destination 3PAR StoreServ’s and issued the following 3PAR CLI commands to observe behaviour state.
- showrcopy groups SRMTEST01*
- Shows state of the remote copy group at each location
- showrcopy links
- Shows the status of the remote copy links at each location
- showvv
- Shows the virtual volume information at each location
Planned Failover
Planned Failover is when both the source and target sites are both up.
The table below shows the observed behaviour on the 3PAR StoreServ at both the source and target sites along with the SRM workflow step
| SRM Workflow Step | Source RG Name | Source Role | Destination RG Name | Destination Role | Sync State |
| Pre Failover | SRMTEST01 | Primary | SRMTEST01.r398979 | Secondary | Synched/Synching |
| Planned Failover | SRMTEST01 | Primary | SRMTEST01.r398979 | Primary-Rev | Stopped |
| Reprotect | SRMTEST01 | Secondary-Rev | SRMTEST01.r398979 | Primary-Rev | Synced/Syncing |
| Planned Failback | SRMTEST01 | Primary | SRMTEST01.r398979 | Secondary | Stopped |
| Reprotect | SRMTEST01 | Primary | SRMTEST01.r398979 | Secondary | Synced/Syncing |
Unplanned Failover – Source Site Down
An Unplanned Failover is when the source site is down and the target site is up.
Before the Unplanned Failover workflow is instigated, the 3PAR StoreServ, vCenter and SRM virtual machines are isolated in the source site.
Note: This particular test this was performed during production hours with users accessing the source virtual machines for business as usual activities. I will create a further blog post on how to achieve this.
The table below shows the observed behaviour on the 3PAR StoreServ behaviour at both source and target sites along with the SRM workflow step when the inter site link is down.
| SRM Workflow Step | Source RG Name | Source Role | Destination RG Name | Destination Role | Sync State |
| Unplanned Failover | SSRMTEST01 | Primary (Unconfirmed) | SRMTEST01.r398979 | Primary-Rev | Stopped |
The details below describe the behaviour observed and any error messages encountered.
- 60 seconds is the timeout value for 3PAR remote copy to see the inter site link as down
- showrcopy grounds SRMTEST01* command ran to verify that SyncStatus field displays ‘stopped’
StoreServ-7200 cli% showrcopy groups SRMTEST01*
Name Target Status Role Mode Options
SCC_SRMTEST01.r398979 StoreServ-7200 Stopped Secondary Periodic Period 15m, over_per_alert
LocalVV ID RemoteVV ID SyncStatus LastSyncTime
SRMTEST01_DR 14096 SRMTEST01_PR 16598 Stopped 2015-04-21 14:22:57 BST
- showrcopy links command ran on target 3PAR StoreServ to verify partner link is down
StoreServ-7200 cli% showrcopy links
Remote Copy System Information
Status: Started, Normal
Link Information
Target Node Address Status Options
StoreServ-7200 0:3:1 172.16.1.10 Down
StoreServ-7200 1:3:1 172.16.1.11 Down
receive 0:3:1 receive Up
receive 1:3:1 receive Up
- Target SRM Server Error Message displayed

- Target SRM logs checked which shows this is an expected behaviour as part of the SRM workflow, the target SRA tries to contact the source SRA but fails as the site is down.
Message [2015-04-21 14:35:47.272 ‘arrayMgm.GetRCTargetSysInfo’ 3PAR_3031 verbose (Process id=1652) (Thread id=1)] Complete: Info. Call. –> [2015-04-21 14:35:47.272 ‘discoverDevices.Run’ 3PAR_1013 error (Process id=1652) (Thread id=1)] Error. Peer array id <39897> is not a valid entry in the connected HP 3PAR Storage Server.
Unplanned Failover – Source Site Up
Inter site link re-established and source site checks are performed which entail:
- Services checked on source vCenter and SRM Server
- SRM Service is stopped, expected behaviour as cannot communicate with vCenter. SRM Service started
The next step is CRITICAL in the SRM workflow. At this point the source and target sites both hold primary read/write copies of data.
SRM at the source site believes that replication is continuing and that nothing has changed!
A device refresh is needed to enable to leverage the HP 3PAR SRA to discover the state of the 3PAR StoreServ arrays. Once done the ‘Failover in Progress’ should be displayed.
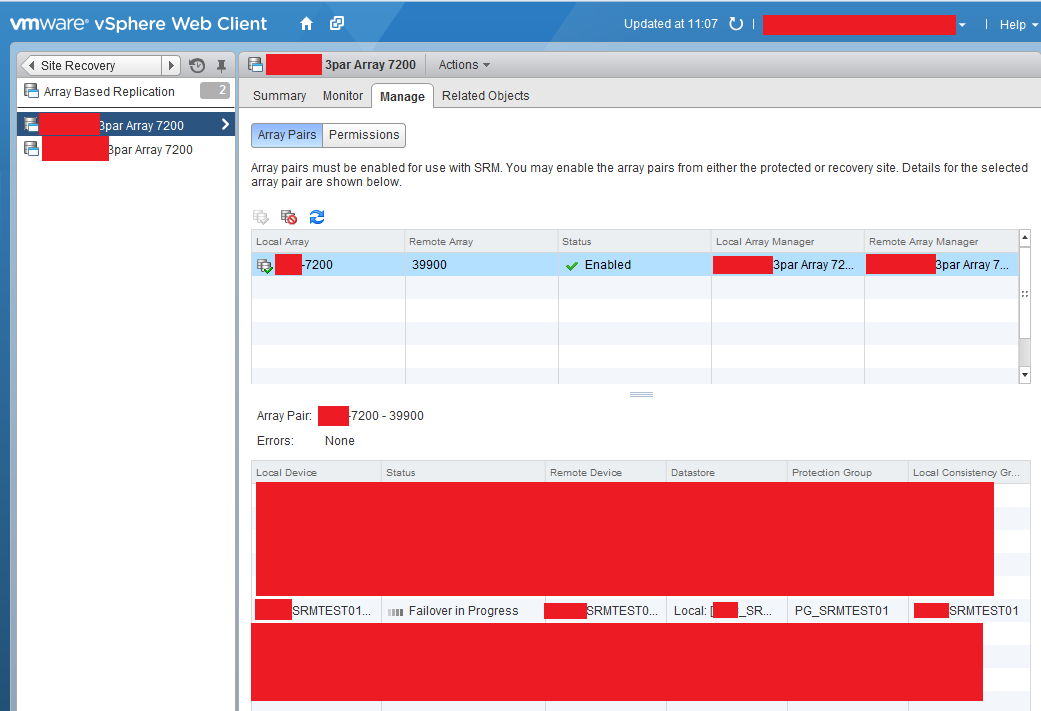
The table below shows the observed behaviour on the 3PAR StoreServ behaviour at both source and target sites along with the SRM workflow step when the inter site link is up.
| SRM Workflow Step | Source RG Name | Source Role | Destination RG Name | Destination Role | Sync State |
| Source Site Up | SRMTEST01 | Primary | SRMTEST01.r398979 | Primary-Rev | Stopped |
| Planned Failover | SRMTEST01 | Primary | SRMTEST01.r398979 | Primary-Rev | Stopped |
| Reprotect | SRMTEST01 | Secondary-Rev | SRMTEST01.r398979 | Primary-Rev | Synced/Syncing |
| Planned Failback | SRMTEST01 | Primary | SRMTEST01.r398979 | Secondary | Stopped |
| Reprotect | SRMTEST01 | Primary | SRMTEST01.r398979 | Secondary | Synced/Syncing |
Final Thoughts
Using 3PAR StoreServ with Site Recovery Manager provides an easy to use workflow orchestration. However it is critical to understand the behaviour of each dependency and identify and remediate any action which is not expected.
The key step in an unplanned failover is to refresh your devices once the inter site link is re-established. If this is not done, you will asking SRM to perform a workflow which is out of synch with the 3PAR StoreServ which will result in a rebuild of your SRM environment and a call to HP and VMware support.