
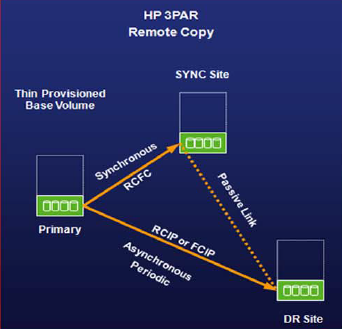
Remote Copy is the term 3PAR StoreServ uses for replicating Virtual Volumes either synchronously or ‘a synchronously’. The last time I spoke to HP, they mentioned that the highest supported latency for synchronous replication RTT was <1.7ms.
I have been fortunate enough to have configured a number of 3PAR’s with VMware’s Site Recovery Manager and setting up and configuring the Storage Replication Adapter (SRA) was a breeze. The only downside was that when you performed a test failover it always failed until you changed the Advanced VMFS3 setting to
VMFS3.HardwareAcceleratedLocking 0
One of the things I disliked about Remote Copy was the fact that if you couldn’t have ‘synch’ and ‘a synch’ Remote Copy Groups. The great news is this has now been changed and with 3PAR OS 3.1.2 we can have booth, hoorah!
However, something which I don’t really understand is that HP only support a two node system (which is a common deployment) using both Remote Copy Fiber Channel and Remote Copy IP for ‘synch’ and ‘a synch’ Remote Copy Groups. Not sure how many people have both fiber and ethernet presented from intersite links?
3PAR StoreServ 7000 now supports vSphere Metro Storage Cluster using Peer Persistence (later in this blog post), it mentions that up to 5ms RTT is supported, however I’m pretty sure that the user experience would be somewhat dire to say the least, can you imagine waiting for the acknowledgement on the remote array?
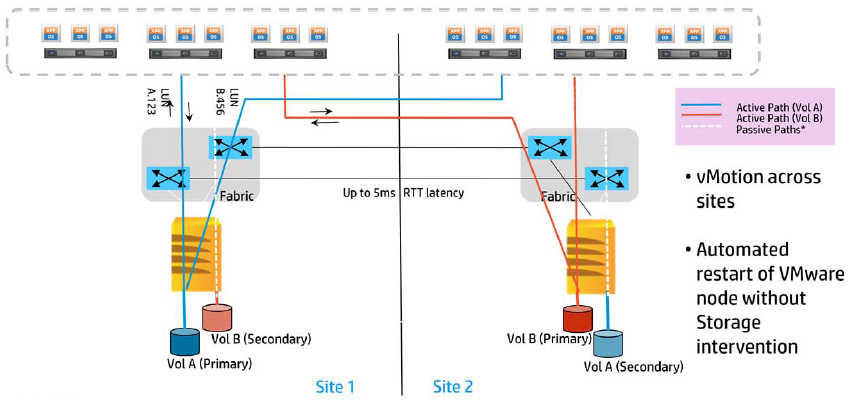
- Think of the intersite link (ISL) usage, would enough bandwidth be available to continue synch replication?
- If a VM’s datastore is at the other end of the ISL then you are using very ineffective routing
- Should always be used with Enterprise Plus licenses so you can instigate should Storage DRS rules to ensure that VM’s should always use the datastores they are in the same site as.
From a 3PAR StoreServ perspective the Virtual Volume is exported with the same WWN to both arrays in Read/Write mode, however only the Primary copy is marked as Active, the Secondary copy is marked as Passive.
At the time of writing this post, the failover is manual, as a quorum holder has not been created yet. I’m sure it won’t be long and 3PAR will have something like the Failover Manager (FOM) that StoreVirtual uses.
A few of other points to know about Remote Copy are:
- Supports up to eight FC or IP links between 3PAR StoreServs
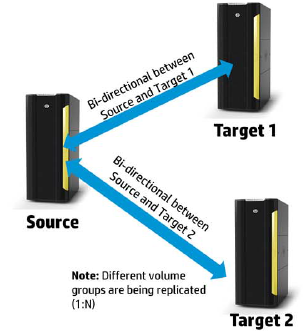
- Supports replication from one StoreServ to two StoreServ for added redundancy
My overall experience with Remote Copy in Inform OS 3.1.1 has been that of frustration, a lot of the work has to be done via the CLI as the GUI has a nasty habit of not sending the correct commands or for some reason Remote Copy Links not establishing. A few of the commands that I have used on a regular basis are:
startrcopy
admitrcopylink <3PARName> 2:6:1:<targetIP> 3:6:1:<targetIP>
controlport rcip addr <targetIP> 255.255.255.0 2:6:1
controlport rcip addr <targetIP> 255.255.255.0 3:6:1
controlport rcip gw <gatewayIP> 2:6:1
controlport rcip gw <gatewayIP> 3:6:1
controlport rcip speed 100 full 3:6:1
One of the things I think is a great feature of Remote Copy on 3.1.2 is Remote Copy Data Verficiation, which allows you to compare your read/write (Primary) volume and your read (Secondary) volume. To implement this you run the ‘checkrcopyvv’ command which creates a snapshot of the read/write (Primary) volume and then cmopares it to the read (Secondary) volume. If inconsistencies are found then only the required blocks are copied across.
Note that only one checkrcopyvv can be run at a time.
With 3PAR OS 3.1.1. you have always been able to perform bi-directional remote copy, however now it is supported!
- Synchronous Remote Copy – 800 Volumes
- Asynchronous Remote Copy – 2400 Volumes
Peer Persistance
I mentioned above that Peer Persistence has been included to allow support for vSphere Metro Storage Cluster so how does it work?
- Asymmetric Logical Unit Access (ALUA) is used to define the target port groups for both primary and secondary 3PAR StoreServ.
- The Remote Copy volumes are created on both arrays and exported to the hosts at both sites using the same WWN’s in Read/Write mode, however only one site has active I/O, the other site is passive.
- When you switch over, the primary volumes are blocked and any ‘in flight’ I/O is trained and the group is stopped and failed over.
- Target port groups on the primary site become passive and the secondary site become active.
- The blocked IO on the primary volumes becomes unblocked and a sense error is created indicating a change of target port group to the secondary volumes
- Remote Copy Group is updated and the restarted replicating in the other direction.
To move across your would use the command setrcopygroup switchover <group> to change the passive to active without impacting any I/O.

There are a few risks with Peer Persistence firstly it shouldn’t be used with a large number of virtual volumes (no exact numbers from HP yet). The reason for this is the switch over could take more than 30 seconds as a snapshot is taken at both the primary and secondary site just in case the operation fails e.g. ISL goes down. Worst case scenario you would need to promote a volume manually.

One thought on “3PAR StoreServ 7000 Software – Part 7”