One of the key concern areas for clients who are considering migrating workloads into Microsoft Azure is failures. Why would this be a concern, isn’t that the responsibility of Microsoft to ensure that they meet the 99.9% or greater SLA? Well the answer is no.
It is up to you to ensure that your applications are ‘cloud ready’ and can be split between fault and update domains to achieve the stated 99.95% SLA.
This means the onus is on you to ensure that your application is split across geographic locations with multiple instances. Ensuring that global site load balancing is in place along with data integrity and zero data loss if you loose an instance member. Of course all of your on-premises applications have been designed to be cloud ready, erm yeah right!
So knowing that most of our on-premises applications aren’t designed to be ‘cloud ready’ what is the impact and expected behaviour outside of Microsoft’s mandated SLA with availability sets?
Fabric Controller
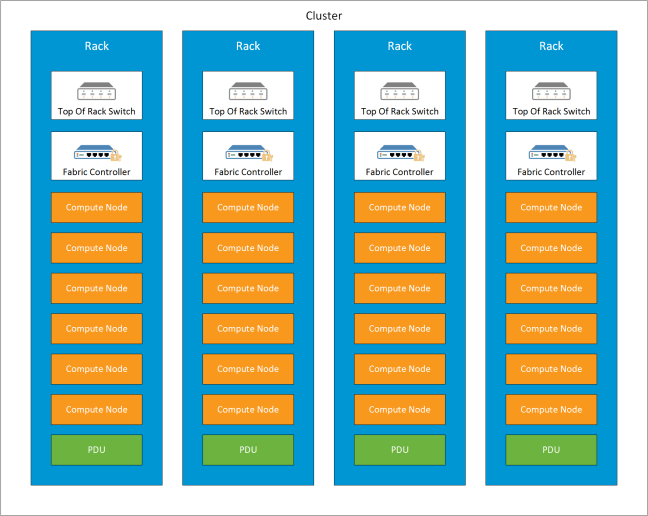
This is where we need to introduce the Azure Fabric Controller. Each Microsoft Azure datacentre is split into clusters which are a grouping of racks. These provide compute and storage resources. Each cluster is managed by a Fabric Controller which is a distributed stateful application running across servers spread across racks. The purpose of the Fabric Controller is to perform the following operations:
- Co-ordinates infrastructure updates across update domains
- Manages the health of the compute services
- Maintains services availability by monitoring the software and hardware health
- Co-ordinates placement of VM’s in Availability Sets
- Orchestrates deployment across nodes within a cluster
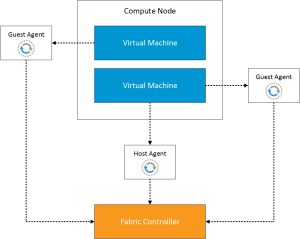
The Fabric Controller receives heartbeats from the physical host and also the guest virtual machines running on the host.
Now that we understand the architecture, let’s cover a couple of failure scenarios.
Guest VM Unresponsive
If the Fabric Controller fails to receive a number of heartbeats from the Guest VM, then it is restarted on the same physical host.
Physical Host Failure
In the event of a physical host failure, the virtual machine is powered on a different physical host. To do this your virtual machine must be protected by Locally Redundant Storage (LRS maintains three copies of synchronous data within the same datacentre).
The Fabric Controller determines which compute node has the same level of storage that your original VM was on and then powers on the read only VHD and changes it to read/write.
Final Thought
To achieve the 99.95% SLA you need applications which are ‘cloud ready’. However you are still protected against Guest VM and Physical Host failures in the same way that you use on-premises vSphere or Hyper-V HA. However as mentioned in this post, Microsoft does not provide an SLA against this.
Interestingly Microsoft does not provide an SLA against a datacentre failure. It is only when Microsoft declares a datacentre lost that the geo-replicated copies of your storage become available. Due to this it is important that you understand that you have zero control over the datacentre failover process.

As an IT professional mired in Azure for the last 5 years, I have to say it’s the biggest pile of shit they’ve ever dropped on the world. But our leaders keep buying it up, convinced it will turn around someday, when it never should’ve left beta. Don’t think you’ll be able to stay on-prem for much longer, they’re pushing everything and everyone into this monolithic monstrosity. Soon, you’ll be drowning in their non-stop & ever recurring “preview-state” cloud crapplications, none living up to the hype they purport. Their tech support? Forget about it. See you all in the cloud soon!