We received a report from a client that the local site Exchange DAG had been falling over on a regular basis.
After some investigation we noticed that Exchange 2010 had changed from block level replication to file level replication with Event ID 10036, MSExchangeIS Mailbox Store
‘Continuos replication block mode is unable to keep up with the data generation rate. Block mode has been suspended, and file mode has been resumed’.
We performed various tests and the net result that a ping from one DAG member to the other resulted in > 4ms latency. Not good!
This meant that when the Exchange 2010 cluster threshold was reached which is latency above 1ms for a period of 5 seconds, the DAG failed over, causing users Outlook clients having to relocate which server they mailbox resided on.
For a quick fix we changed ran the following Exchange 2010 Power Shell commands:
cluster /list
cluster.exe ‘cluster name’ /prop
Increased the SameSubnetDelay threshold by running:
/cluster.exe /cluster:’cluster name’ /prop samesubnetdelay=2000
/cluster.exe /cluster:’cluster name’ /prop samesubnetthreshold=2000
This means that the DAG will no longer failover, however it doesn’t resolve the underlying issue with the network latency.
I was concerned from a vSphere perspective as the client has vCentre Operations Manager which hadn’t alerted on any issues with bandwidth utilisation and the no other latency issues had been reported by end users.
What did I do to diagnose the issue? As it’s always good to know your peers thought process!
– Checked all vSwitches Uplinks to make sure no configuration changes had been made and that they all reported back as 1000 Full – Pass
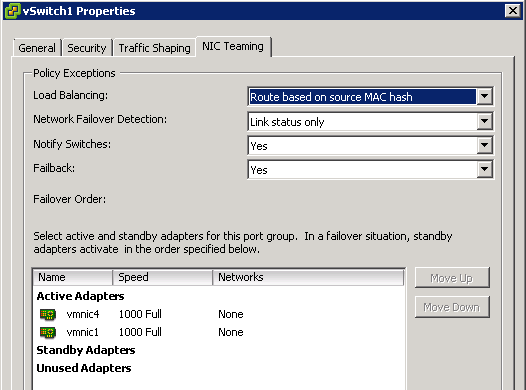
– Checked Load Balancing on vSwitches, default as ‘route based on originating virtual port ID’ – Pass
– Checked Network Utilisation in Exchange VM’s, all reporting < 10 Mpbs – Pass
– Checked Performance Charts for Network Utilisation on ESXi Hosts, not above 300 Mbps for past month- Pass
– Checked ESXTOP, to ensure that VM’s correctly balanced across uplinks see post What NIC is my virtual server using – Pass
– Checked physical servers on same LAN which always reported back <1ms response times – Pass
– Checked CPU/Memory utilisation on Cisco 4510 switches all below 20% – Pass
– Checked VMware Update Manager, some hosts needed updates (7 in total) – Failed
My colleague was looking at various port counters on the Cisco 4510 switches and he noticed that flow control was enabled and the TXPause counter was increasing on the ports that the ESXi hosts where connected. We turned off flow control and didn’t notice any difference.
By default Flow Control is enabled on ESX and ESXi but only comes into play if the switch you are connected too supports it, see this article
We updated all of the ESXi Hosts using VUM as it had various E1000 adapter updates. However the issues continued to persist.
At this point, we knew this issue wasn’t going to be a quick fix and would require some more investigation as the issue could be any of the following:
– E1000 vNIC
– Cisco 4510
– Broadcom NetXtreme II BCM5709 (standard for HP and Dell servers for onboard NIC)
On this particular configuration we have HP2810G switches which are isolated from the LAN and are used for vMotion, Fault Tolerance Logging and MS Clustering Heartbeats.
Step 1 – Pass
We setup a couple of test VM’s on different ESXi Hosts and created a new ‘test’ vSwitch using an Intel 82571EB Adapter with VMXNET3 adapters on an isolated VLAN. Monitored this for a day we received all response times <1ms.
Step 2 – Pass
To ensure that the TCP/IP stack in Windows 2008 R2 VM’s was reset and to remove those pesky hidden network adapters, we ran the following commands:
netsh winsock reset
netsh int ip reset
Removed Intel 82571EB Adapter from ‘test’ vSwitch and replaced with a Broadcom NetXtreme II BCM5709 VMXNET3 adapters on an isolated VLAN. Monitored this for a day we recieved all response times <1ms.
Step 3 – Fail
Ran the same TCP/IP commands for Windows 2008 R2 VM’s.
netsh winsock reset
netsh int ip reset
Stayed with the Broadcom NetXtreme II BCM5709 bu changed vNIC to E1000 adapters on an isolated VLAN. Monitored this for a day we recieved some response times <4ms.
Step 4 – Fail
We now know that the E1000 vNIC was a cause of the issue, however we needed to go back to the VMXNET3 on the main LAN.
Again we ran reset the TCP/IP stack to remove any hidden network adapters.
Stayed with the Broadcom NetXtreme II BCM5709 bu changed vNIC to VMXNET3 adapters on LAN. Monitored this for a day we received all response times <3ms.
Conclusion
What have we learnt? Well the first thing is to change the virtual machine vNICs to VMXNET3 which reduces the latency across the LAN, however this is not acceptable as it should always be <1ms unless you have a broadcast storm.
The second thing is to replace the 4510’s, as they have been end of life for over 2 years.