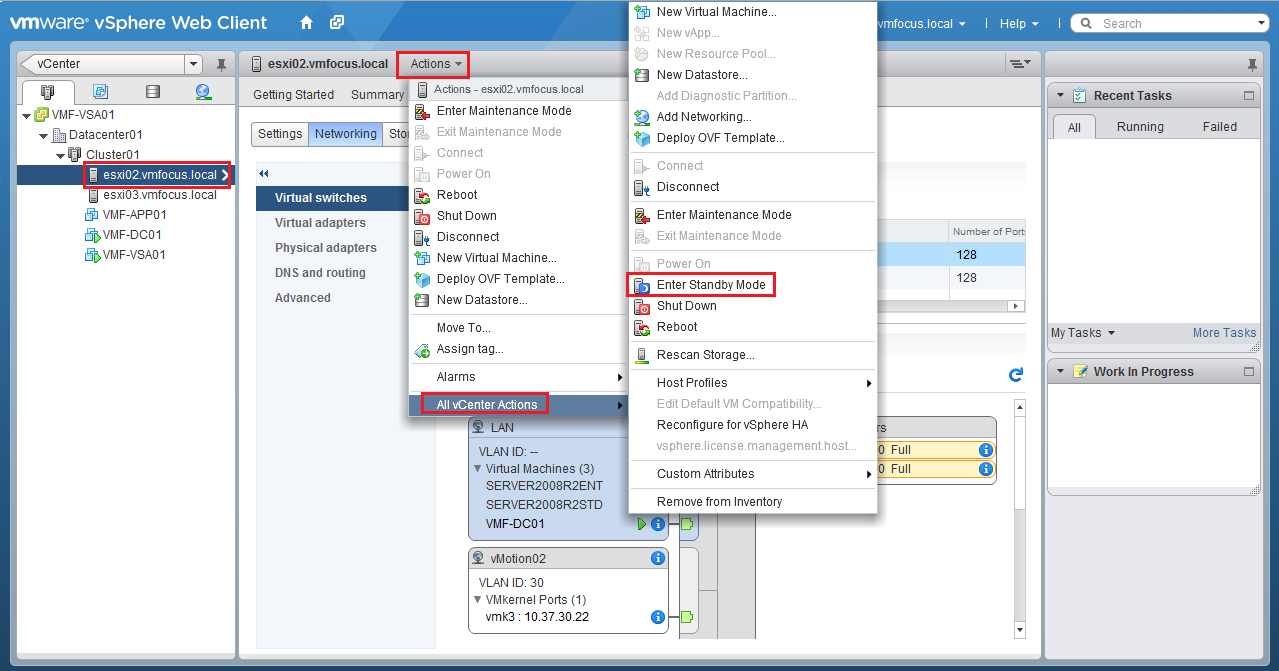
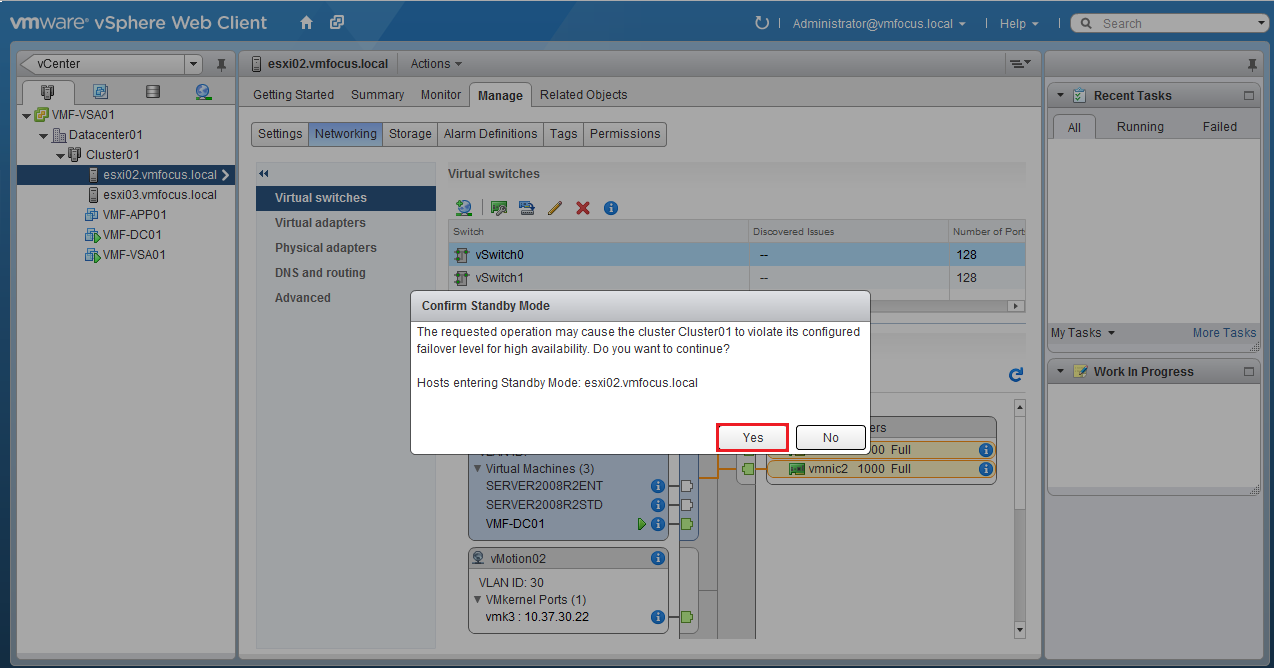
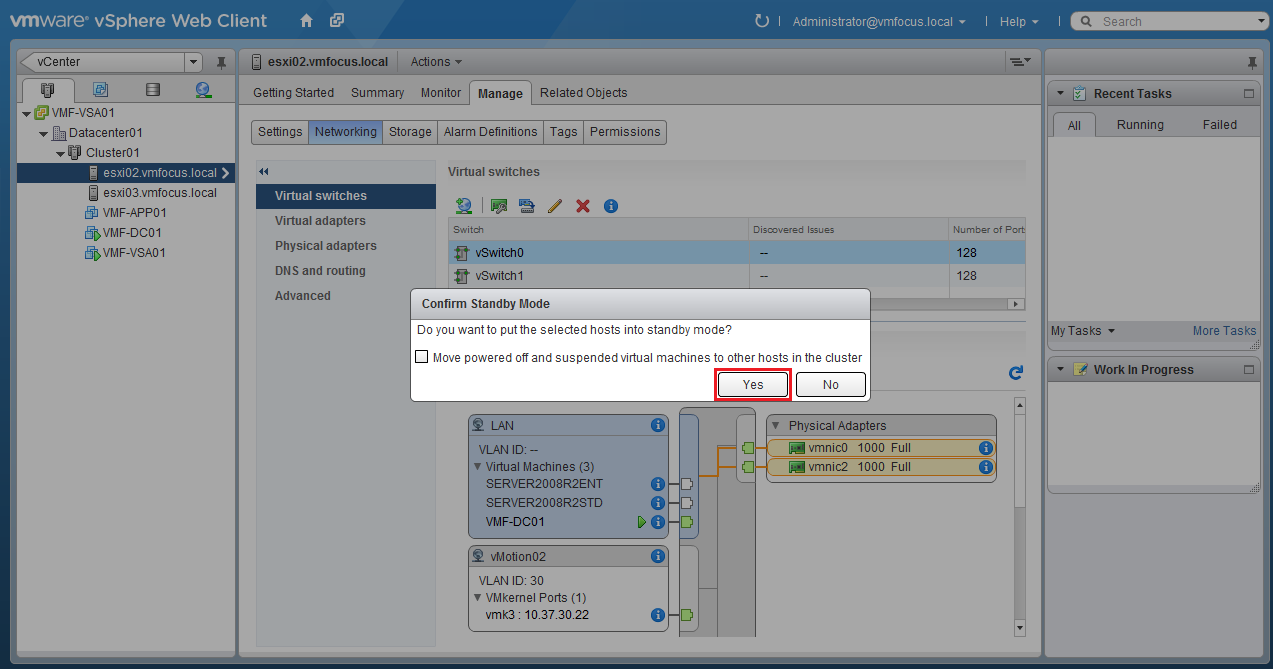
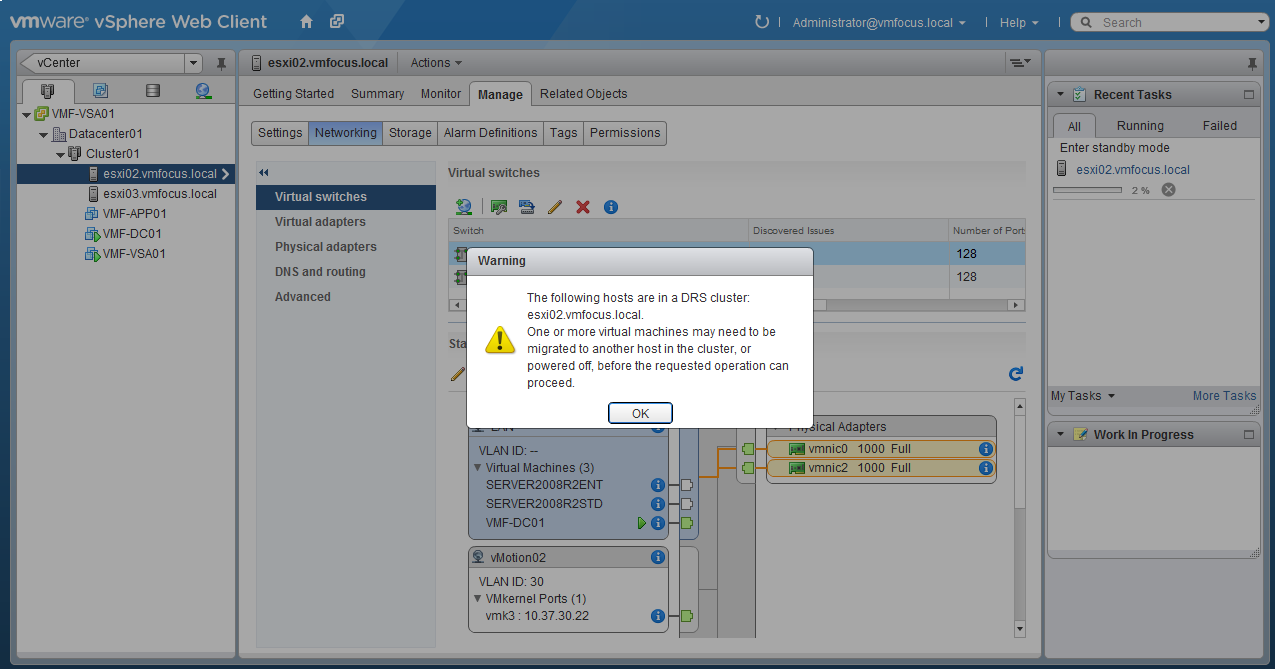
First of all, what does S3 stand for? The answer is Simple Storage Service which was launched by AWS in March 2006, so it’s over 13 years old at the time of writing this blog post!
S3 provides developers and IT teams with a secure, durable and highly scalable object storage. Examples of object storage are flat files such as word documents, PDFs, text documents etc.
S3 allows you to securely upload and control access to files from 0 bytes to 5TB into a ‘Bucket’ which is essentially a folder. The ‘Bucket’ requires a globally unique namespace across S3. AWS claim that S3 provides unlimited storage (not sure if anyone would or could test this claim!).
Data Consistency
S3 uses the concept of read after write consistency for new objects. In a nutshell this means when the object is committed to S3, you can read it.
However when you are updating or deleting the object you receive eventual consistency. So if you have a file which you have just updated and you access it immediately, you may get the old version, wait a few seconds and you will receive the new version.
S3 The Basics
S3 is built for 99.99% availability, however AWS only provides a 99.9% availability SLA see here. Which means you could have just over 8 hours 40 minutes of acceptable downtime per annum.
Think about the impact of AWS S3 availability SLA on any designs
Amazon provides a 99.999999999% (11x9s) durability SLA which means data won’t be lost. However does this same guarantee apply to data integrity?
S3 provides the option for tiered storage with lifecycle management, for example if an object is older than 30 days move it to a lower cost/class tier.
Outside of this, S3 allows versioning of objects, encryption and policies such as to delete an object you have to use MFA.
S3 Storage Tiers/Classes
At the time of writing this blog post, S3 offers six different classes of storage. Each of these has it’s own availability SLA, differing levels of costs and latency.
It’s easiest to explain this in the table below which is taken from AWS.

If we look at all of the different storage classes except for S3 One-Zone IA they can suffer the loss of two availability zones. Whereas only S3 Standard and S3 Intelligent-Tiering includes data retrieval fees.
Lastly if we examine ‘first byte latency’ this determines how quickly you will be able to access any objects.
Replication
When you create an S3 ‘Bucket’ you are able to replicate this from one AWS region to another, providing either high availability or disaster recovery (dependent on your configuration). This can also be coupled with S3 Transfer Acceleration which uses CloudFront edge locations. The benefits this provides are that users upload files to the closest of AWS’s 176 edge location which are then transferred securely to the S3 Bucket.
The diagram below provides a logical overview of this process.

A few things to note about S3 Cross Region Replication:
- Only new objects and changed objects are replication, not existing objects
- Cross Region Replication requires versioning to be enabled
- The target bucket can use a different storage class
- The target bucket receives the same permissions as the source bucket
- Deletions and deletion markers are not replicated from the source to target region
Security
S3 security is achieved by a number of elements, which include encryption in transit using TLS and at rest when the data is committed to the S3 bucket.
Dependent on how a business operates it may choose to either handle encryption at rest locally and then upload the encrypted object to the S3 bucket or trust AWS to encrypt the object within the bucket. This process is managed by keys to encrypt and decrypt the object.
- S3 Managed Keys – Built Into S3, managed by AWS
- AS Key Management Service – Managed by both AWS and the customer
- Server Side Encryption with Customer Keys – Customer provides the keys
By default a bucket is private e.g. the objects within this are not accessible over the internet. You can apply access policies to a bucket either on the resource directly or via a user policy.