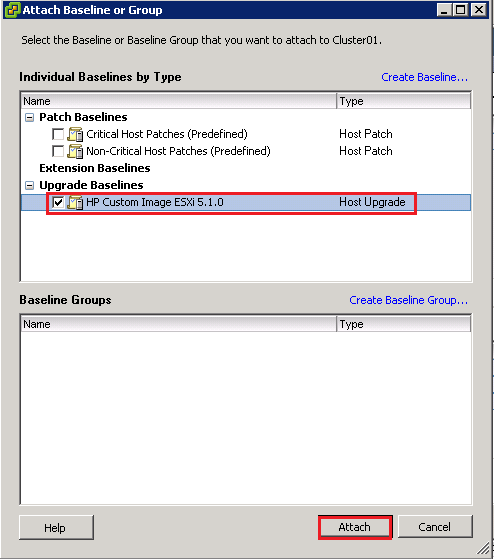
I had an interesting point raised on the blog today from Colin over at Solori.net He suggested changing the IOPS=QUE_DEPTH to see if I can decrease my storage latency. I wasn’t able to find any settings to alter the queue depth on HP StoreVirtual and I’m not fortunate enough to have a Fiber channel SAN kicking around, so I don’t have the ability to change an HBA setting. However this got the grey matter whirring , what about changing the Software iSCSI Queue Depth in ESXi5.1?
Before we get into the testing, I think it’s an idea to go over how a block of data gets from a VM to the hard disks on your NAS/SAN.
- Application e.g. Word Document
- Guest VM SCSI queue
- VMKernel
- ESXi vSwitch
- Physical NIC
- Physical Network Cable
- iSCSI Switch Server Port
- iSCSI Switch Processor
- iSCSI Switch SAN Port
- Physical Network Cable
- iSCSI SAN Port
- iSCSI Controller
I actually feel sorry for the blocks of data, they must be knackered by the time they are committed to disk.
At the moment I’m sending 1 IOP down each iSCSI path to my HP StoreVirtual VSA. The results of this was an increase in overall IOPS performance, but an increase in latency see blog post Performance Increase? Changing Default IOP Limit
The Software iSCSI Queue Depth can be verified by going into ESXTOP and pressing U (LUN)
SSDVOL02 is naa.6000eb38c25eb740000000000000006f which has a Disk Queue Depth of 128

IOMeter will let us know the overall latency which is what the Guest OS sees, which is great, but what we care about is knowing where the latency is happening. This could be in one of three places:
- Guest VM SCSI queue
- VMKernel
- Storage Device
I have spun up a Windows 7 test VM, which has 2 vCPU and 2GB RAM. Again for consistency I’m going to use the parameters set out by http://vmktree.org/iometer/
The Windows 7 test VM is the only VM on a single RAID 0 SSD Datastore. It is also the only VM on the ESXi Host. So we shouldn’t expect any latency due to compute resources being in constraint.
We are going to use ESXTOP to measure our statistics using d (disk adapter) u (LUN) and v (VM HDD) and collate these with the IOMeter results.
The focus is going to be on DAVG/cmd KAVG/cmd and QAVG/cmd these are related to
DAVG/cmd is Storage Device latency.
KAVG/cmd is VMKernel Device latency
GAVG/cmd is the total of DAG/cmd and KAVG/cmd
QAVG/cmd is Queue Depth of our iSCSI Software Adapter

Taken from Interpreting ESXTOP Statistics
‘DAVG is a good indicator of performance of the backend storage. If IO latencies are suspected to be causing performance problems, DAVG should be examined. Compare IO latencies with corresponding data from the storage array. If they are close, check the array for misconfiguration or faults. If not, compare DAVG with corresponding data from points in between the array and the ESX Server, e.g., FC switches. If this intermediate data also matches DAVG values, it is likely that the storage is under-configured for the application. Adding disk spindles or changing the RAID level may help in such cases.’
Our Software iSCSI Adapter is vmhba37
Note that for the ESXTOP statistics, I took these at 100 seconds into each IOMeter run.
Default 128 Queue Depth

Right then let’s make some changes shall we.
I’m going to run the command esxcfg-module -s iscsivmk_LunQDepth=64 iscsi_vmk which will decrease our Disk Queue Depth to 64.
This will require me to reboot ESXi03 so I will see you on the other side.
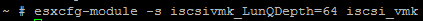
Let’s verify that the Disk Queue Depth is 64 by running ESXTOP with the U command.

Altered 64 Queue Depth

Let’s run the command esxcfg-module -s iscsivmk_LunQDepth=192 iscsi_vmk which will increase our Disk Queue Depth to 192. Then reboot our ESXi Host.
Again, we need to verify that the Disk Queue Depth is 192 by running ESXTOP with the U command.

Altered 192 Queue Depth

So the results are in. Let’s compare each test and see what the consensus is.
Comparison Results – IOMeter
The table below is colour coded to make it easier to read.
RED – Higher Latency or Lower IOPS
GREEN – Lower Latency or Higher IOPS
YELLOW – Same results

Altering the Software iSCSI Adapter Queue Depth to 64 decreases latency by an average of 3.51%. IOPS are increase on average by 2.12%
Altering the Software iSCSI Adapter Queue Depth to 192 decreases latency by an average of 3.03%. IOPS are increase on average by 2.23%
Comparison Results – ESXTOP
The table below is colour coded to make it easier to read.
RED – Higher Latency or Lower IOPS
GREEN – Lower Latency or Higher IOPS
YELLOW – Same results

Altering the Software iSCSI Adapter Queue Depth to 64 decreases latency between Storage Device and Software iSCSI Initiator by an average of 0.06%. VMKernel latency is increased by 501.42%.
Altering the Software iSCSI Adapter Queue Depth to 192 increases latency between Storage Device and Software iSCSI Initiator by an average of 6.02%. VMKernel latency is decreased by 14.29%.
My Thoughts
The ESXTOP GAVG compares to the latency experienced by IOMeter for 32KB Block 100% Sequential 100% Read and 32KB Block Sequential 50% Read 50% Write. I could put the differences down to latency in the Guest VM iSCSI queue.
However, the differences between ESXTOP GAVG and IOMeter for 8KB Block 40% Sequential 60% Random 55% Read 35% Write and 8K Block 0% Sequential 100% Random 70% Read 30% Write are vastly different. If anyone has some thoughts on this, that would be appreciated.
Overall altering the Software iSCSI Adapter Queue Depth to 64 gave a slightly performance increase for IOPS and latency, however not enough for me to warrant changing this full time in the vmfocus.com lab.
Final note, you should always follow the advice of your storage vendor and listen to there recommendations when working with vSphere.