As part of my day job, I review vSphere infrastructures giving recommendations on areas which could be potential concerns. Many of the business’s that I see engaged consultants to perform the initial installation and configuration and hand vCenter/vSphere back to the internal IT department. Overtime, changes are made and settings are updated without consideration to what they mean.
So with this in mind, I decided to put together this blog post ’10 Things To Check Quickly in vCenter’
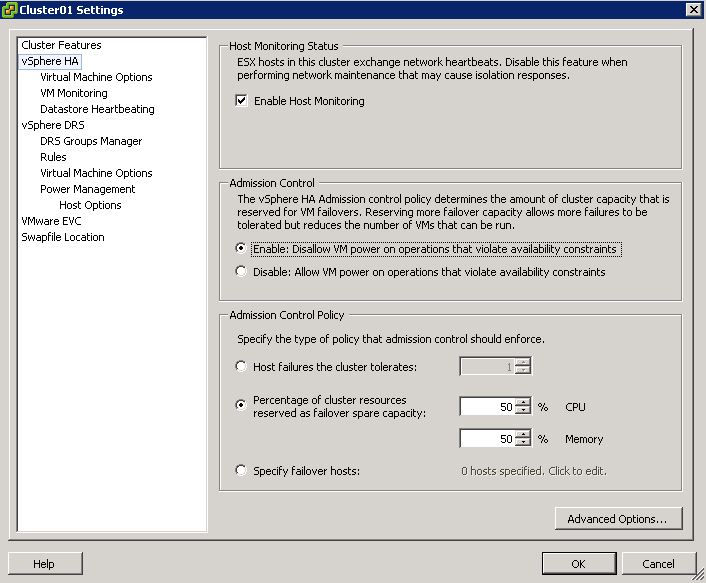
1. Admission Control
The whole point of admission control is to ensure that you have the redundancy within your infrastructure to tolerate a failure of some description, more often than not this is N+1. So check your admission control is first of all enabled and secondary it is set correctly e.g. 2 x ESXi Hosts should be 50% CPU and 50% Memory
I have seen countless installations where this has been turned off to enable an new VM’s to be ran and the hosts where never upgraded to compensate for this increase in workload.

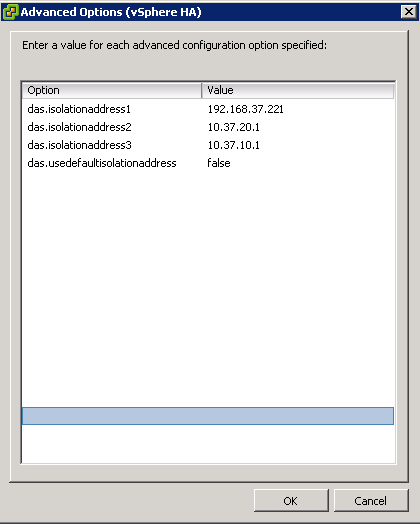
2. DAS Isolation Address
The default setting is a single isolation address which is your default gateway. What happens if this goes down in a vSphere 4.1 environment? Well man down is the reaction! Ensure that you specify numerous IP address, I commonly go for:
1. Layer 2 switch IP address used for vMotion/FT
2. SAN management IP address
3. LAN/Management default gateway IP Address

3. VM Monitoring
Turn this on, I know the default is disabled, but that’s not an excuse. Why wouldn’t you want vSphere to monitor your VM’s and restart them if it has no network or datastore activity?

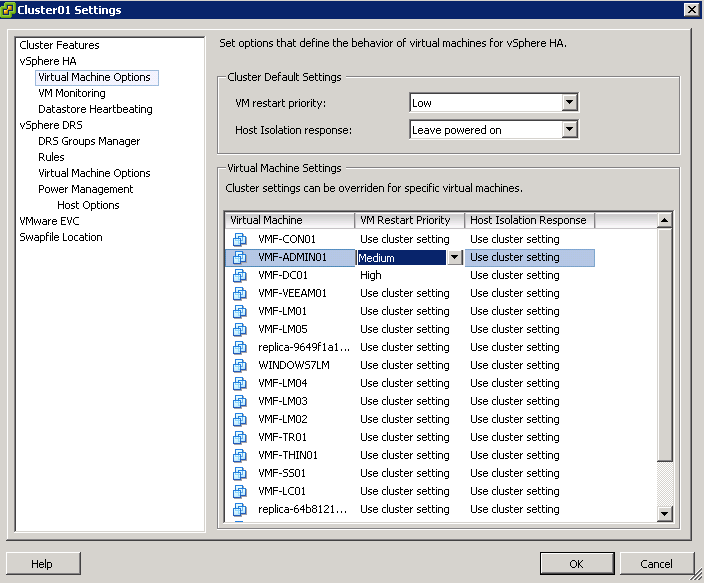
4. VM Restart Priority
Let’s start with the premise that not all virtual machines are equal. If you have virtualised Domain Controllers you would want these to be high priority restarts, followed by SQL and then application servers that connect to SQL. I wrote a blog post on this a while back click me.
Take a few minutes and check with your server team to ensure that if you do have a failure then you have done your best to bring applications up in the right order.

4. DRS Rules
Spend some time working with application team creating sensible DRS Anti Affinity and Affinity rules. Some examples are:
- Anti Affinity – Domain controllers to be running on the same ESXi host?
- Anti Affinity – SQL Cluster with RDM
- Anti Affinity – XenApp/Terminal Server farm members
- Affinity – BES and SQL

5. VMware Update Manager
I quite often see environments where VMware Update Manager hasn’t been installed and if it has you can almost guarantee that the ESXi Hosts/VM/vApp haven’t been patched.
Without being flippant, there is a reason my VMware release patches/updates which is generally for bug fixes or security issues.

6. Alerting
Check to make sure that you have a valid SNMP/SMTP server setup, as after infrastructure migrations these settings can often be wrong.
Also take some time to configure alerting at ‘root’ level in vCenter to make sure they meet you business needs. If you aren’t sure what to implement, I wrote a couple of blog posts on this subject to get you started:
Setting Up & Configuring Alarms in vCenter 5 Part 1
Setting Up & Configuring Alarms in vCenter 5 Part 2

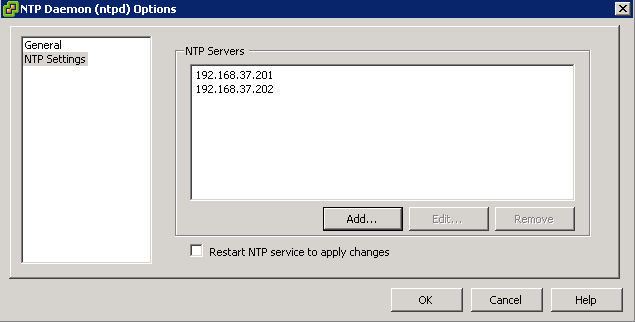
7. Time Configuration
Virtual Machines take there initial time settings from the ESXi host. We all know what dramas can happen if your virtual machines are more than 15 minutes out of sync with your domain controllers. Use your internal domain controllers as your NTP Servers for your ESXi Hosts, it stops unnecessary NTP traffic going traversing firewalls and ensures that you won’t be affected with time skew.

8. Virtual Machines With ISO’s Attached
We all pop ISO’ onto Local Storage on ESXi Hosts as it’s not taking up valuable space on our SAN. The worse thing we can do is forget that we have them attached as if HA needs to come into action, these VM’s are going to fail.
Either check your Local Datastores on a regular basis or if you have lots of ESXi Hosts, then use tools such as PowerGUI with the VMware Management pack installed to script it.

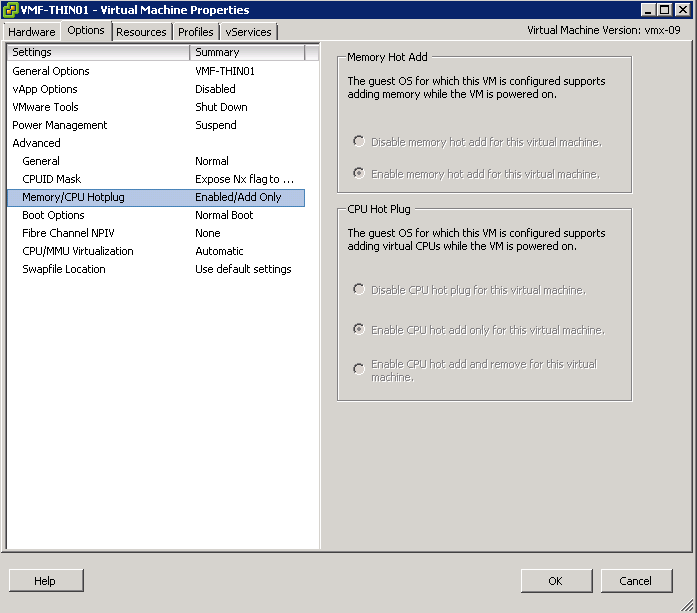
9. Hot Add Memory/CPU
Virtual Machine workloads change over time, why cause unnecessary downtime and potential evening or weekend work for yourself? Make sure that you enable Memory and CPU Hot Add on your templates.

10. Resource Pools
The golden rule is know what you are doing with resource pools as if you go into resource contention they are going to come into play. I have seen resource pools used as containers/folders, resource pools created at cluster level to protect ‘high importance’ VM’s which result in these VM’s having less resources to use! A quick explanation of this can be found over at Eric Sloof’s site NTPRO.NL